The fifth Accelerator programme has now finished and we have 29 graduates from 21 organisations with the skills and technical knowledge to make a real contribution to data science across the public sector.
This is a significant achievement in just a short space of time, and we’ve just done our first cohort with two new ‘hubs’ running in Sheffield and Newport. We are reaching further across the country than ever and making sure that data science is seen as fundamental to effective policy and operations.
For each Accelerator cohort we run national events to make all the hubs feel joined up, and that includes a graduation to celebrate successes. We wanted to share some of these success stories here on our blog.
Alan Lewis (Greater London Authority)
Alan wanted to identify where housing benefit claimants live, and whether the pattern is changing, in order to improve local authority budget forecasting. He used de-identified DWP monthly summaries of housing benefit claims by location (Lower Layer Super Output Areas), and clustered 17 million data points about claimant characteristics to produce this map:
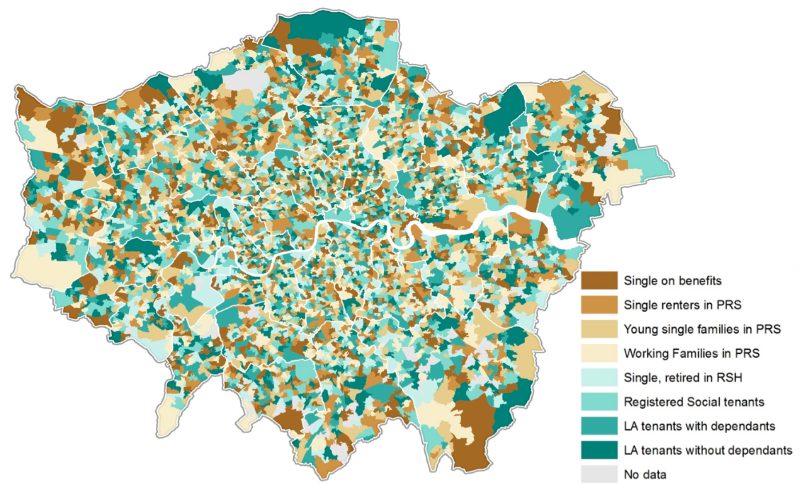
As the map shows, London is a patchwork - although there is some evidence emerging on areas that are consistently popular with working families. Alan went on to apply a pattern recognition technique (k Nearest Neighbours) to investigate how the clusters have changed and to explore any correlations in their distribution.
Further work is underway and Alan is working with some individual London Boroughs to validate his initial results and investigate how welfare reform changes could be driving some changes seen.
Richard Boland (Department for Education)
Richard built a web app using Python’s Django library to help his colleagues at the Education Funding Agency prioritise resources. Using machine learning, the app predicts financial and governance risks associated with an Academy Trust, so that resource can be prioritised towards the cases where it is most useful. It applies Latent Dirichlet Allocation to the action plan text from Academy Trusts’ Financial Management and Governance Self-Assessments (FMGS). In order to bring the data to life and put it in context with the history of the submitting Academy Trust, Richard also developed a D3 force-directed graph to represent the journey of individual academies from Trust to Trust.
The final product is not publicly available, but since the end of the project Richard has put his new skills to use to build another web app to inform his work on sampling strategies.
Adam Bray (Education Funding Agency)
Adam worked on forecasting construction inflation to predict the cost of building works at schools and therefore allocate budget more efficiently.
Adam used Python to implement both a Grey Model and an Autoregressive Integrated Moving Average Model (ARIMA), and found that it was possible to forecast inflation to within an error of around 3% for short time horizons. This model will be used in construction market intelligence for school building.
Sarah Culkin (Department of Health)
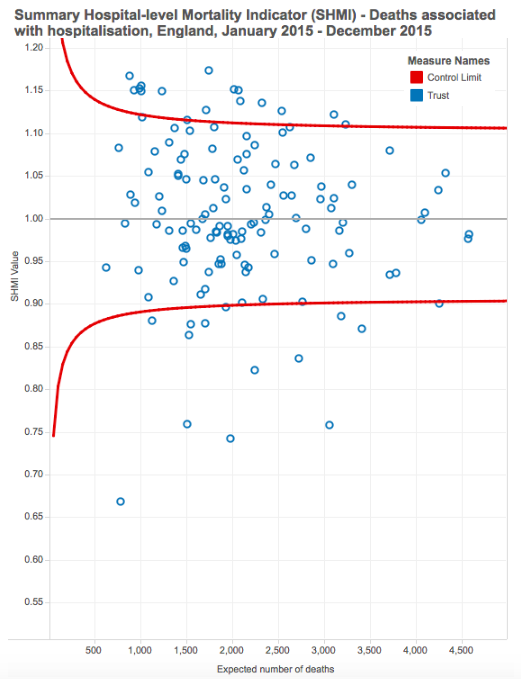
How do we know if too many patients died in a hospital? Explaining the concept of ‘expected patient deaths’ statistics to non-statisticians is a challenge that Department of Health analysts regularly encounter. To help clinicians and senior managers understand this concept and make more use of these statistics, Sarah developed an interactive tool to visualise how the Summary Hospital-Level Mortality Indicator (SHMI) formula works. She used Python’s Flask library to produce the app, which is deployed on Heroku, and SVG to produce the tool’s animations. The tool is currently being tested before being rolled out to NHS managers.
Matthew Dray (DEFRA)
Foulbrood is a bacterial disease that kills honey bees by destroying bee larvae. Bees are critical to our agriculture industry and the UK food supply so preventing foulbrood is very important. Matthew worked on identifying areas of highest risk for the disease in order to help beekeepers and conservationists focus limited resources better, and to help beekeepers understand where the threat to their hives come from.
Matthew predicted risk using the Random Forest machine learning algorithm, with disease-incidence data from the National Bee Unit and data on air quality, climate and human factors. Using these, he produced an interactive map in R Shiny to display relative risk across the UK and is discussing its development and use with the Bee Health team.
Richard Dean (Public Health England)
Richard developed a web app using Python’s Django framework to generate work and health profile reports for decision-makers working on Greater Manchester devolution. The Greater Manchester devolution plan includes integration of care provision to address population health problems that are more severe in Greater Manchester than the rest of England. The app presents data through web pages with embedded D3 graphs and downloadable maps and were generated through the browser via the QGIS Python library.
Since completing the data science accelerator scheme, Richard has been working to automate report generation, and using Python to analyse data from PHE’s marketing campaigns such as One You. Richard has also been following a Machine Learning course, with the intention of applying machine learning techniques that were used by others on the accelerator, to tackle some of Public Health England’s data challenges.
Seb Mhatre (Department for International Development)
DfID’s Development Tracker gives details of each of DFID’s International Aid programmes and allows staff to see what progress is made and what tactics and policies have been most effective. Seb scraped data from each project website and extracted data from each project LogFrame into a new format that allows text mining for more efficient searching and comparisons, so that programmes which are trying to achieve similar results can be better identified and aligned, saving money and leading to more effective results.
Andreas Harding (Government Legal Department)
The Civil Service People Survey should be used to improve team performance, but existing reporting from it often isn’t as helpful as it could be. A key user need is to find teams whose managers can share ideas. They may have faced similar issues, but be in different organisations or parts of the country.
Andreas clustered organisations based on the People Survey and separate demographic data, using the affinity propagation algorithm in Python’s scikit-learn library and visualising the results in a web app. As expected, the job questions produced similar clusters, whereas wellbeing, bullying, harassment and demographics clustered very differently. The Cabinet Office team supporting the People Survey are now looking at how Andreas’ analysis could be included in their future work.
Sarah Rae (Department for Transport)
Sarah looked at recently released industry open data about rail fares, in order to support the development of policy on fair fare regulation by looking for any fares which do not fit to the pattern of others. She developed R scripts to process the information she found and produce an updatable database. Ultimately the database became a dashboard with maps and charts showing differences in the price of season tickets across routes, using the Javascript libraries Leaflet and D3, and regressions showing the patterns in the data. This will inform the rail minister’s work to make the fares system fairer for those who use the rail network.
Over to you...
As you can see, Accelerator Cohort 5 had an exciting variety of projects. Cohort 6 is now underway and applications for Cohort 7 have just started. Applications close on 16 September.
