GOV.UK’s search engine is powered by lots of underlying information that isn’t always shown in the main search results. But you can access this valuable metadata through a more technical interface, with filters to get just the details you want.
For GDS performance analysts this is a handy way to supplement the data we collect in Google Analytics and other tools. We can take a list of page URLs and look up the corresponding organisations, content types, topics, last updated dates and more, so we can segment or compare them.
We also use the search API to create content inventories for some projects, narrowing down the results to specific combinations of keywords, organisations, content types and so on. And sometimes we just want to find out how many items there are that match certain conditions.
Ways to read API data
An application programming interface (API) is a way of accessing structured data. The search API uses a common data format called JSON. If you’re not comfortable writing your own code to read this data in a programming language such as Python or R, there are tools that can do most of the hard work for you.
JSON viewers
The raw data looks like a big block of code with lots of brackets. You can make it easier to read using an online tool or browser extension to display the JSON data in a clear tree structure. For example, I use the JSON Formatter extension for Google Chrome.
JSON converters
Various online or downloadable tools can convert data from the API’s JSON format to more familiar spreadsheet-style tables such as CSV files. One example is json-csv.com, which even has options for how to present any nested data (for example if there’s more than one organisation associated with an item).
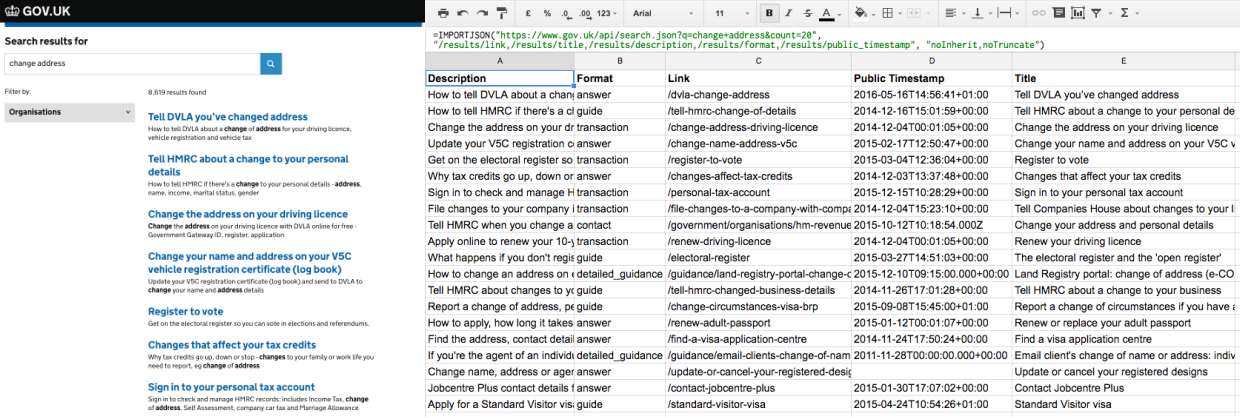
ImportJSON for Google Sheets
If you’ve used the ImportXML function to scrape page data in Google Sheets, you’ll find ImportJSON quite similar. It’s a custom script that’s not built in or supported by Google. It works well for simple fields with only one value, but the current version is buggy with nested data such as multiple organisations or topics.
Here’s a readymade spreadsheet that you can copy and adapt. You’ll need to be signed into Google Sheets, and then go to File > Make a copy. To use the ImportJSON function in a spreadsheet cell, enter the API query URL and the fields to return (see the next section). For example:
=IMPORTJSON("https://www.gov.uk/api/search.json?q=change+address", "/results/link,/results/title")
Accessing the search API
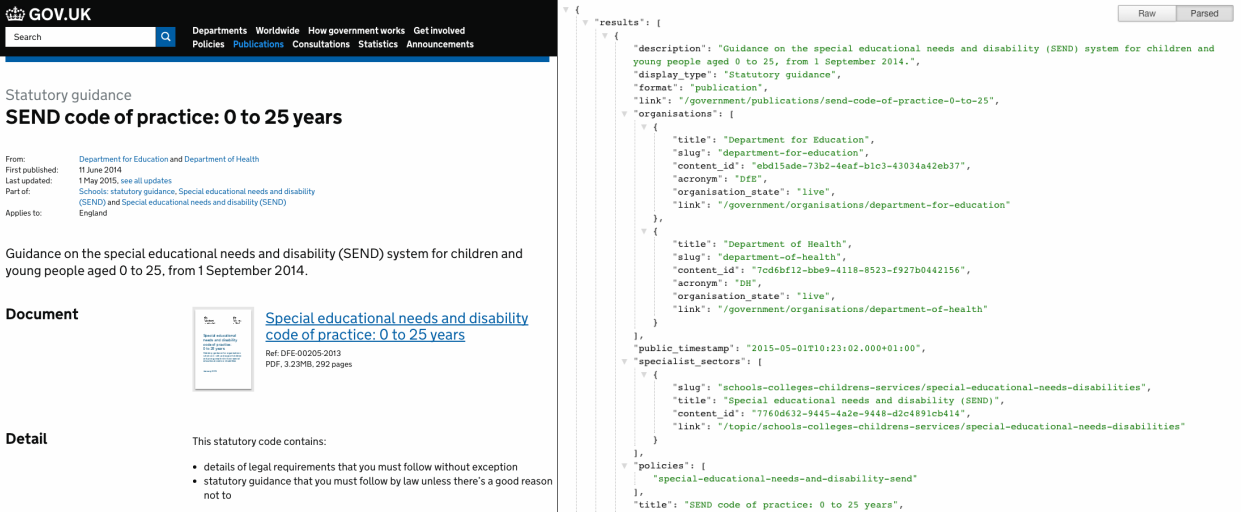
The GOV.UK search API is available at https://www.gov.uk/api/search.json, using query string parameters to set the keywords, sort order and filters you want.
You can combine several parameters by stringing them together with an ampersand (‘&’). This can either narrow down the results, such as filtering by an organisation and a content type, or combine results, such as filtering by two organisations at the same time.
Depending on which tool you’re using, you may need to specify which fields you want it to read. The content metadata is under ‘results’ (for example, /results/title or /results/organisations/acronym), and the ‘total’ field may also be useful.
Metadata for a specific page
To get information about an individual content item, use filter_link= with the page path. For example: https://www.gov.uk/api/search.json?filter_link=/government/publications/apply-for-a-postal-vote
Using a search term
To search for a word or phrase like you would in the standard site search interface, use q= with the search term. For example: https://www.gov.uk/api/search.json?q=car+tax
In the search API this keyword query is optional, so you can just use other filters without a specific search term.
Number of results
By default the search API only returns 10 results per page. To get more results, add count= to the end of the URL, with the maximum number of results you want. For example: https://www.gov.uk/api/search.json?q=jobs&count=100
The limit is 1,000 results per request. To get more than that, you can make further requests using start=, for example: https://www.gov.uk/api/search.json?q=jobs&start=1000. (The numbering starts from 0, not from 1.)
If you just want the totals for a filtered query, without needing the actual results, use count=0. For example, to see how many items there are in the search index: https://www.gov.uk/api/search.json?count=0
Sorting by date or title
To get the newest content, use order=-public_timestamp with a minus symbol for descending order (or for the oldest content, order=public_timestamp without a minus). The public timestamp is the last updated date, except for any minor editorial corrections. For example: https://www.gov.uk/api/search.json?order=-public_timestamp
To sort the results in alphabetical order, use order=title.
Fields
The most common fields are returned by default, though it’s good practice to request only the fields you actually need, which can increase the API’s performance. Specify them by repeating fields= for each one, for example: https://www.gov.uk/api/search.json?fields=link&fields=title&fields=description
Fields will only appear when they exist; some are only relevant for certain content types.
Some fields aren’t returned unless you ask for them, currently including:
| Information | Query parameter |
| Browse sections | fields=mainstream_browse_pages |
| Policies | fields=policies |
| People | fields=people |
| Withdrawn status (true or false) |
fields=is_withdrawn&debug=include_withdrawn |
| History mode status (true or false) |
fields=is_historic |
Withdrawn content
Withdrawn items aren’t currently returned by default, but you can include them in the results by adding &debug=include_withdrawn to the query.
Filtering the search API results
You can filter on suitable fields by adding filter_ in front of the field name. And you can combine several filters with ampersands (‘&’) to get the results you want.
| Filter by | Query parameter | Example |
| Single page | filter_link= | filter_link=/vehicle-tax |
| Organisation | filter_organisations= | filter_organisations=cabinet-office |
| Content type | filter_format= | filter_format=publication |
| Content subtype | filter_display_type= or filter_detailed_format= |
filter_display_type=Open+consultation or filter_detailed_format=open-consultation |
| Topic | filter_specialist_sectors= | filter_specialist_sectors=business-tax/paye |
| Policy | filter_policies= | filter_policies=hs2-high-speed-rail |
| Collection | filter_document_collections= | filter_document_collections=crime-statistics |
| Browse section | filter_mainstream_browse_pages= | filter_mainstream_browse_pages=driving/driving-licences |
| Date range (from and/or to) | filter_public_timestamp= | filter_public_timestamp=from:2016-04-01,to:2016-04-30 |
Excluding items
You can exclude a filter instead of including it, by using reject_ instead of filter_ with any of these filters.
For example, HMRC’s guidance manuals now make up a quarter of the search index. To filter them out and see the total number of remaining items: https://www.gov.uk/api/search.json?reject_format=hmrc_manual&reject_format=hmrc_manual_section&count=0
Filter to find missing fields
The special =_MISSING value returns all the items that don’t have a particular field. For example, to see content that isn’t tagged to any topics: https://www.gov.uk/api/search.json?filter_specialist_sectors=_MISSING
Faceting the search API results
A few of the filterable fields can also be used as ‘facets’, to group the results by that field. For example, to see how many content items each organisation has published: https://www.gov.uk/api/search.json?facet_organisations=1000&count=0
Or to see how many items there are of each content type: https://www.gov.uk/api/search.json?facet_format=1000&count=0
A few caveats
Some of these API fields and filters are likely to change, as part of our work to rebuild GOV.UK’s publishing platform and build a new tagging infrastructure.
Right now, the search index isn’t completely comprehensive. A few content types are deliberately left out, while some others are included but with limited metadata.
For some multipage content types, only the ‘root’ page is included in the search index (for example, /student-finance but not /student-finance/overview or /student-finance/apply).
Over to you
There are lots of potential uses for this data, and we’d love to hear about what you’re doing or how you’re doing it. Please share your ideas in the comments section.
Tara Stockford is a performance analyst at GDS.

4 comments
Comment by John posted on
Great article. Thank you so much. There are also other good online JSON converters such as https://northconcepts.com/tools/json-to-csv/ and https://jsontoexcel.com
Comment by John William Hawkins posted on
How can I check to ascertain if my API details have been received?
John William Hawkins.
Comment by Tim Blackwell posted on
Interesting as a thing in itself and as a basis for improved search. But any attempt to use it returns forbidden.
Comment by Tara Stockford posted on
Sorry if you haven't been able to access the search API; it is meant to be publicly available. We're still looking into these intermittent 'Forbidden' errors.